What is Litmus?

LitmusChaos is a Cloud-Native Chaos Engineering Framework with cross-cloud support. It is a CNCF Incubating project with adoption across several organizations. Its mission is to help Kubernetes SREs and Developers to find weaknesses in both Non-Kubernetes as well as platforms and applications running on Kubernetes by providing a complete Chaos Engineering framework and associated Chaos Experiments.
Litmus can be used to run chaos experiments initially in the staging environment and eventually in production to find bugs and vulnerabilities, fixing which leads to an increased resilience of the system. Litmus adopts a "Kubernetes-native" approach to define chaos intent in a declarative manner via Kubernetes custom resources (CRs).
Importance of Resilience
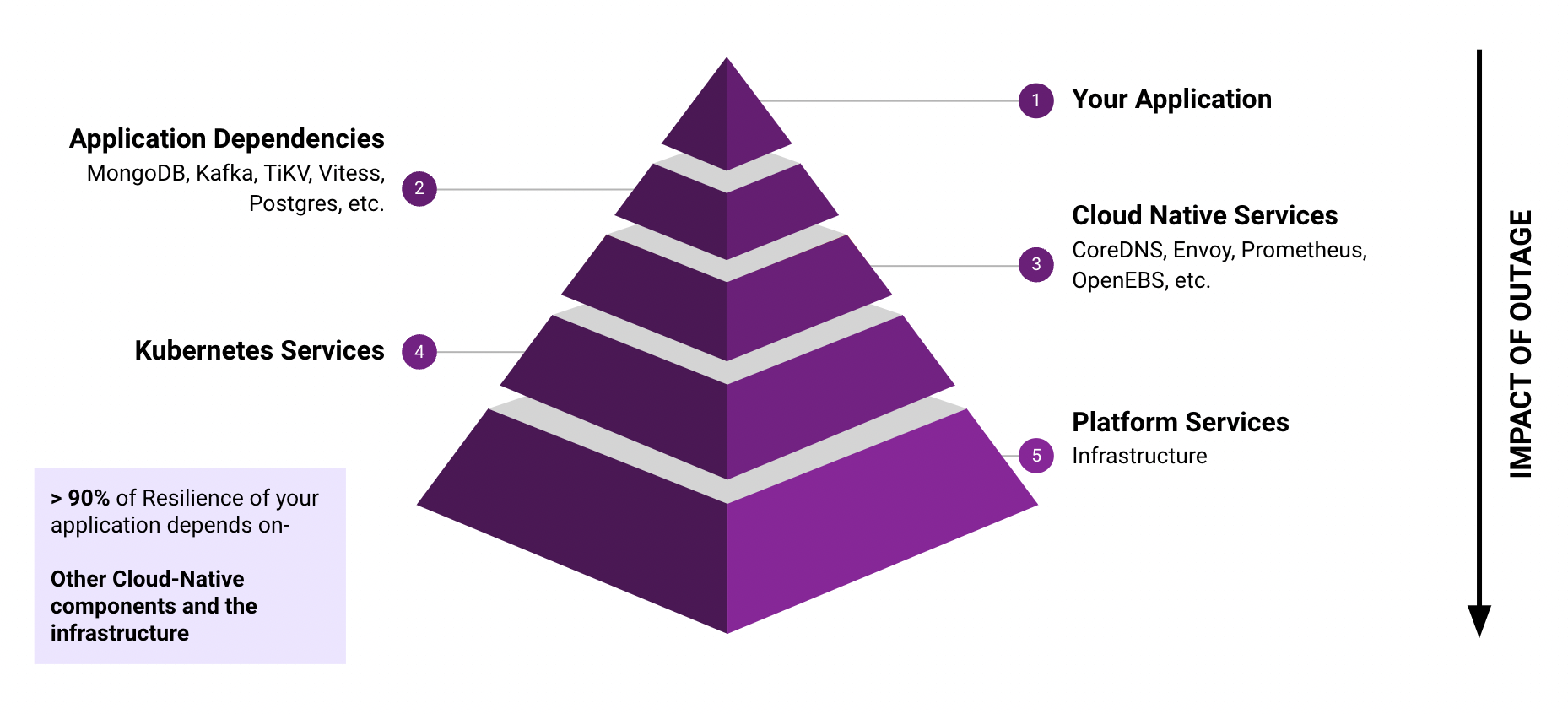
Kubernetes is being run on a variety of infrastructure, ranging from virtual machines to bare metal and a combination of them. The platform’s physical nature is a source of faults to the application that runs inside containers, as shown in the tip of the above diagram. The next layer of dependency is Kubernetes itself.
Your application resilience really depends more on the underlying stack than your application itself. It is possible that once your application is stabilized, the resilience of your service that runs on Kubernetes depends on other components and infrastructure more than 90% of the time.
Thus it is important to verify your application resilience whenever a change has happened in the underlying stack. Keep verifying is the key. Robust testing before upgrades is not good enough, mainly because you cannot possibly consider all sorts of faults during upgrade testing. This introduces the concept of Chaos Engineering. The process of "continuously verifying if your service is resilient against faults" is called Chaos Engineering.
What is a Chaos Experiment
Chaos Experiments are fundamental units within the LitmusChaos architecture. Users can choose between readily available chaos experiments or create new ones to construct a required Chaos Scenario.
What is a Chaos Scenario
A chaos scenario is much more than a simple chaos experiment. It supports the user in defining the expected result, observing the result, analysing the overall system behaviour, and in the decision-making process if the system needs to be tuned for improving the resilience.