Schedule a Chaos Experiment
Before you begin
You must connect an Chaos Infrastructure before scheduling a chaos experiment. You can connect an external Chaos Infrastructure.
Click on the Schedule a chaos scenario button on the home page or Schedule chaos scenario button in Litmus Chaos Scenarios page to get started.
It will take you to the Chaos Studio page where you can choose or design your own chaos scenario by doing the following steps:
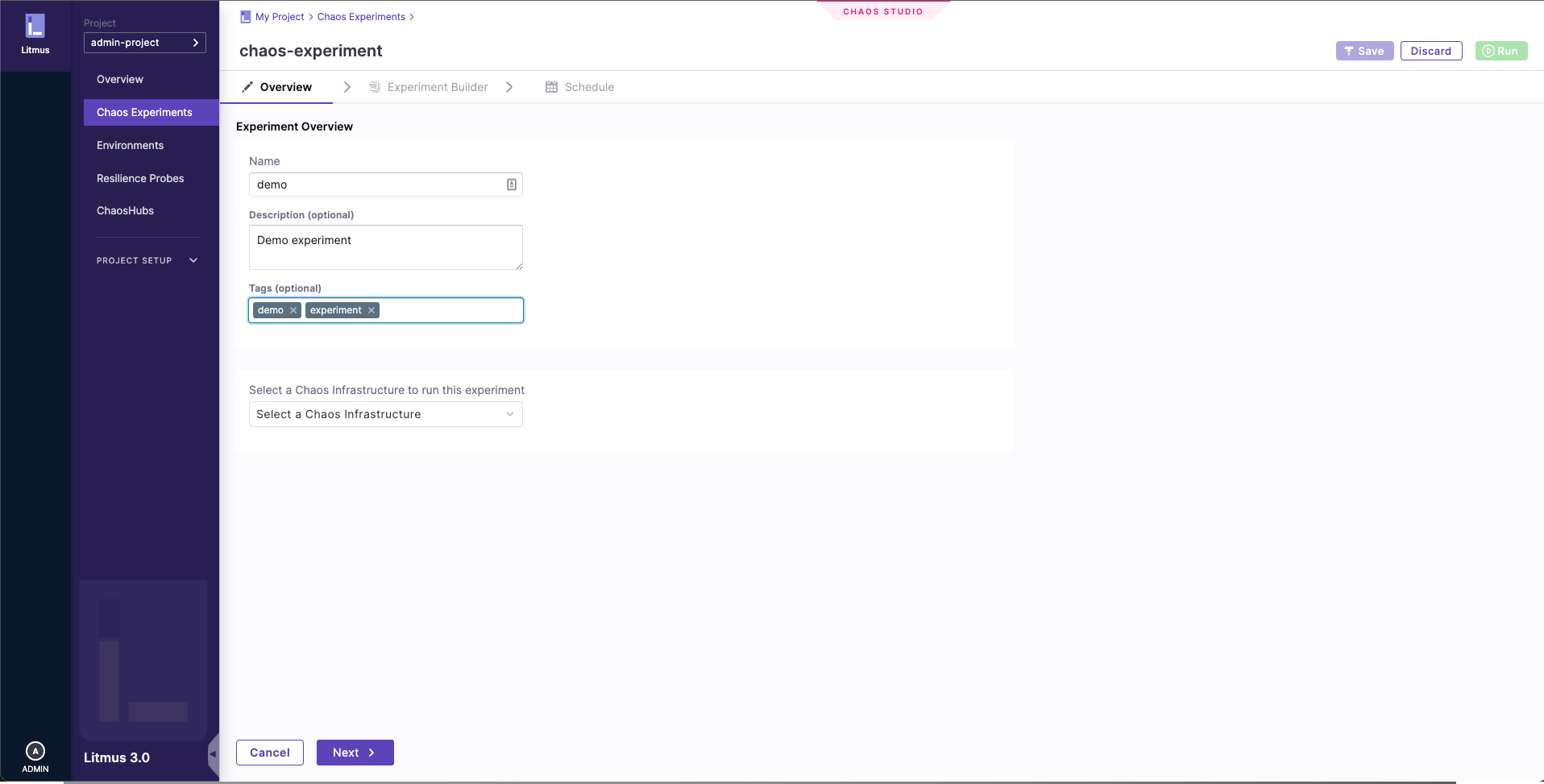
1. Provide the identifiers for the experiment to be created
In the Experiment Overview, enter the experiment Name and optional Description and Tags.
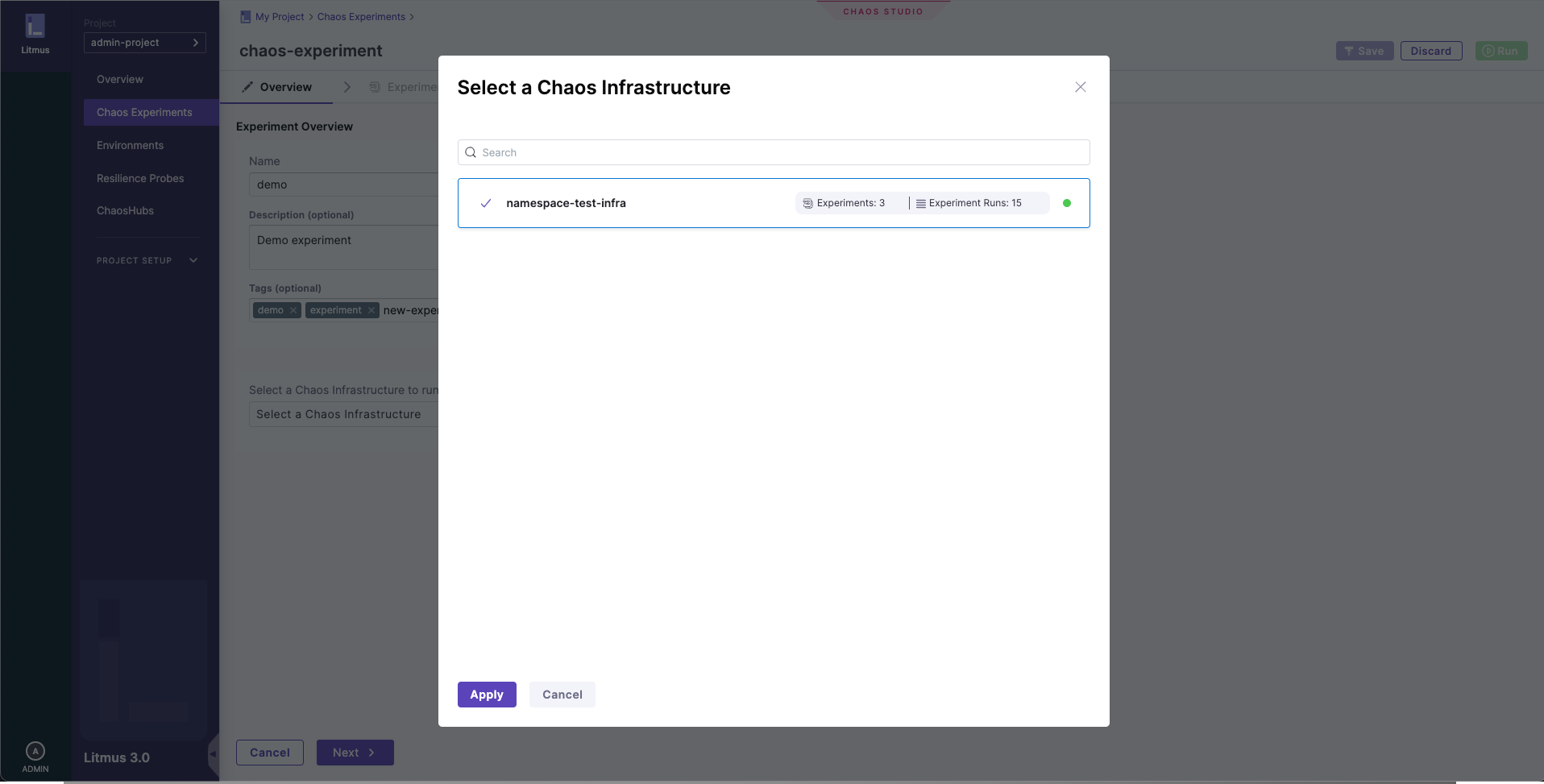
2. Choose target chaos infrastructure
In Select a Chaos Infrastructure, select the infrastructure where the target resources reside, and then click Apply.
After Selecting the chaos Infrastructure , you can continue by clicking on Next button. This takes you to the Experiment Builder tab, where you can choose how to start building your experiment.
3. Choose you want to build your chaos experiment
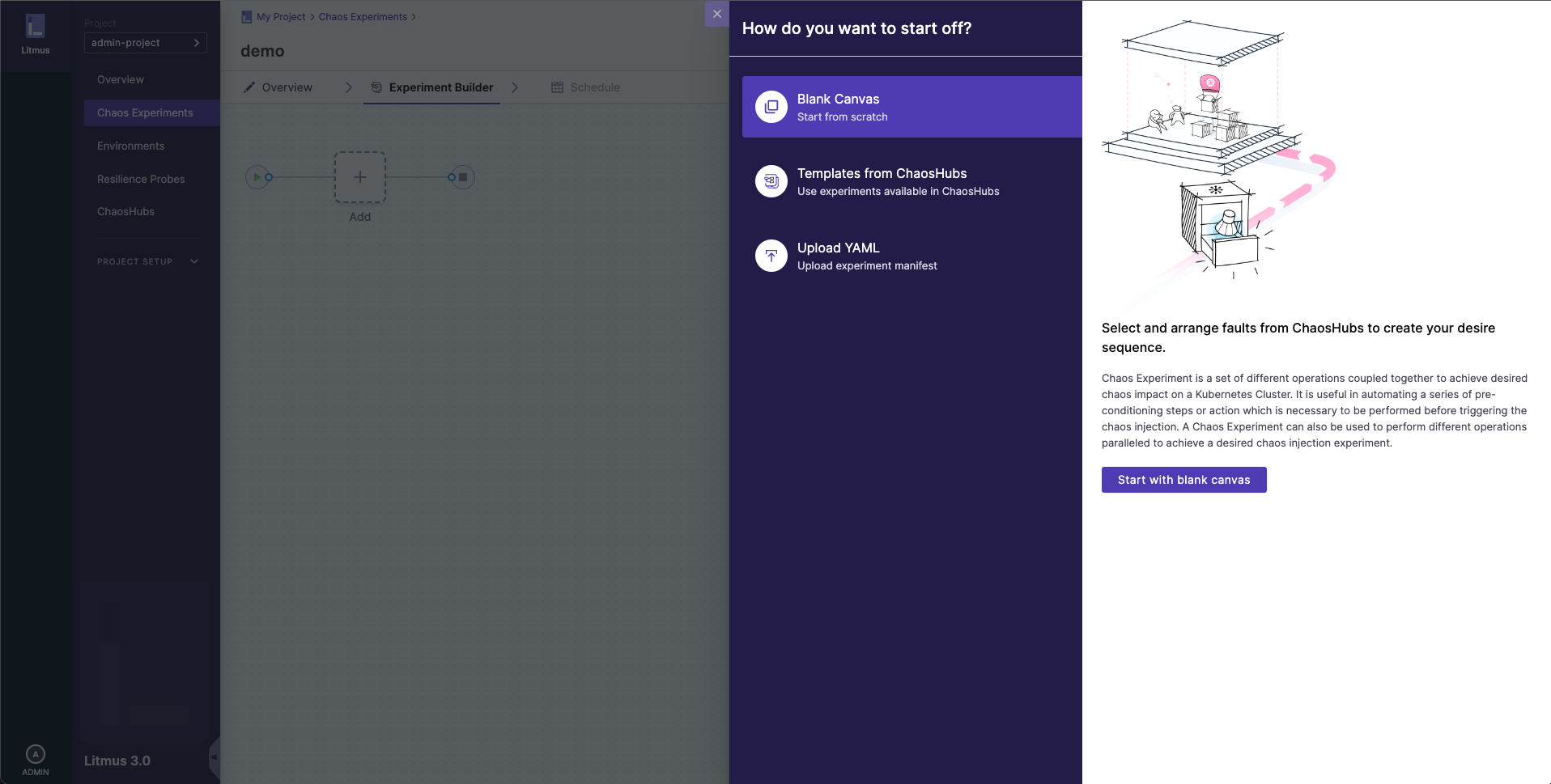
Select how you want to build the experiment. The options, explained later, are:
Blank Canvas - Lets you build the experiment from scratch, adding the specific faults you want.
Templates from Chaos Hubs - Lets you preview and select and experiment from pre-curated experiment templates available in Chaos Hubs.
Upload YAML - Lets you upload an experiment manifest YAML file.
These options are explained below.
If you select Blank Canvas:
The Experiment Builder tab is displayed.
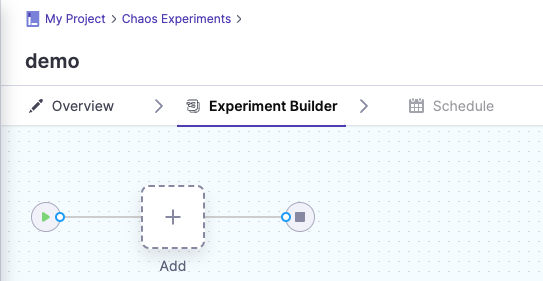
a. Select Add, then select each fault you want to add to the experiment individually.
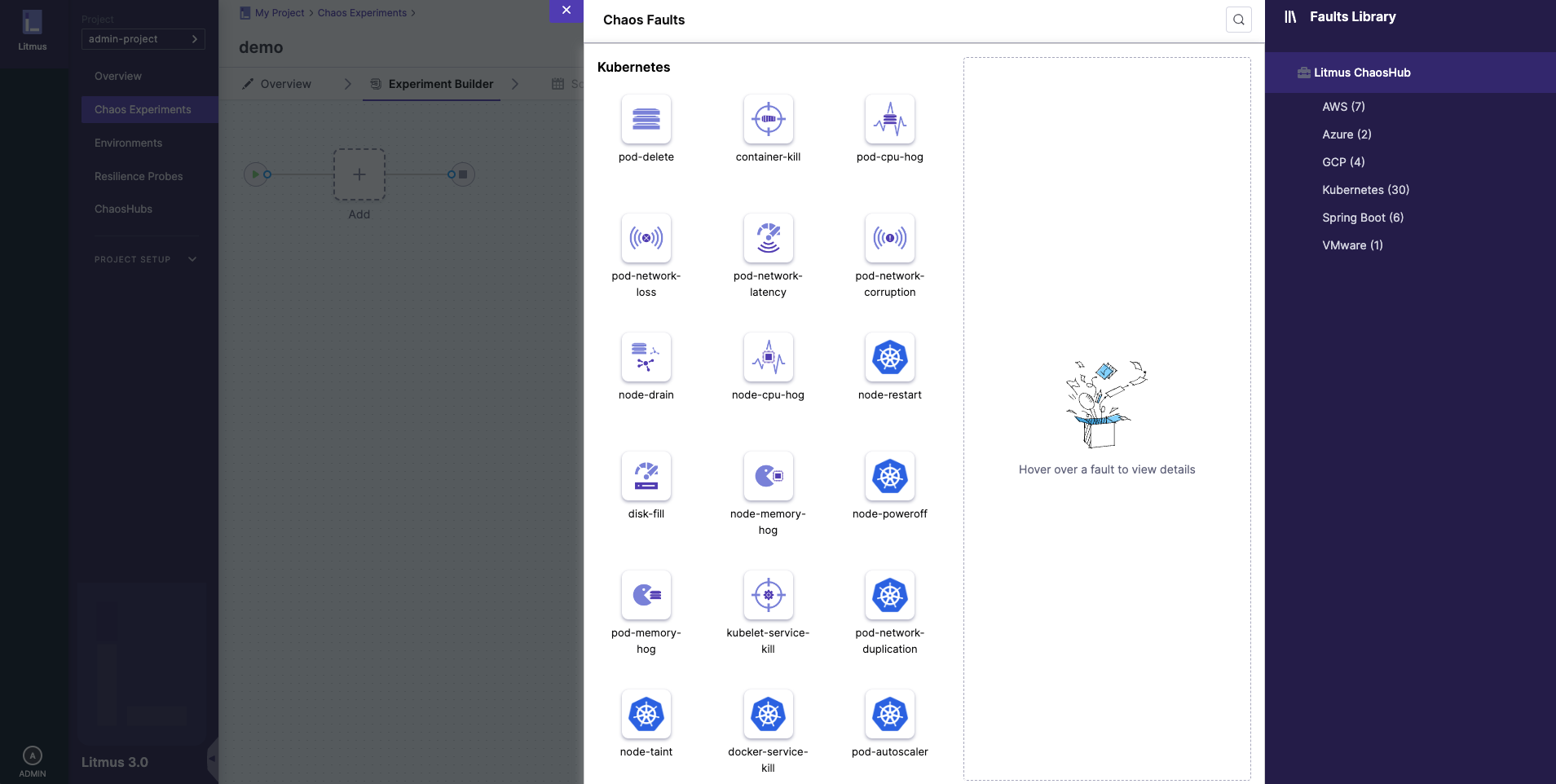
For each fault you select, you'll tune the fault's properties next.
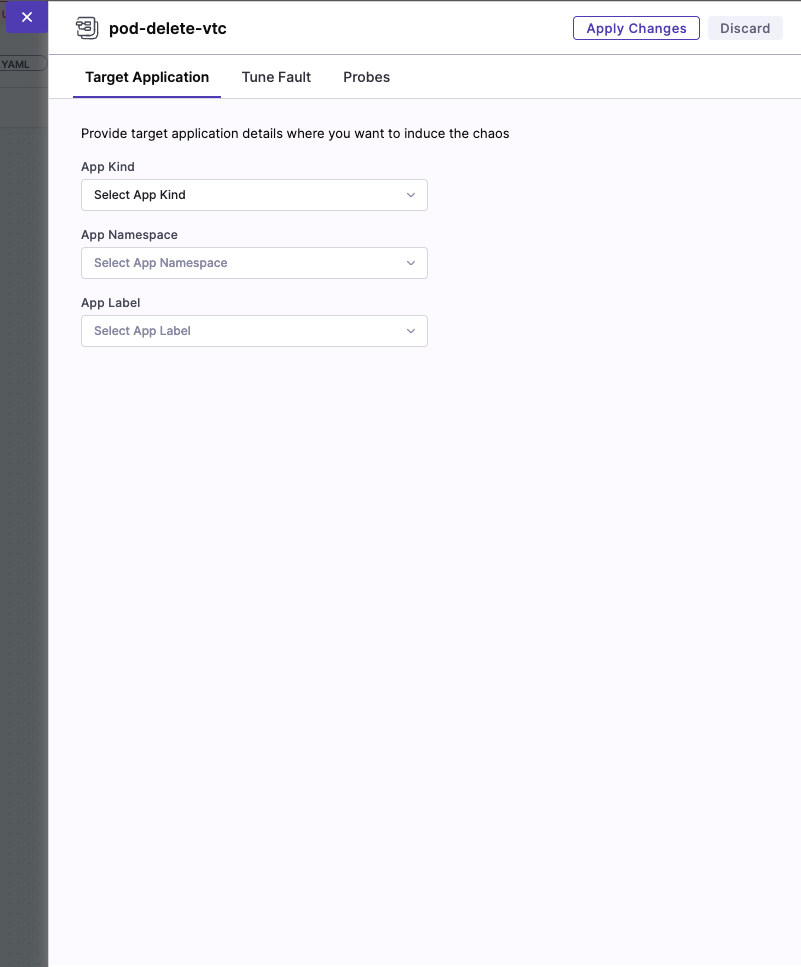
b. To tune each fault:
Specify the target application (only for pod-level Kubernetes faults): This lets the application's corresponding pods be targeted.
Tune fault parameters: Every fault has a set of common parameters, such as the chaos duration, ramp time, etc., and a set of unique parameters that may be customised as needed.
Add chaos probes: On the Probes tab, you can add chaos probes to automate the chaos hypothesis checks for a fault during the experiment execution. Probes are declarative checks that aid in the validation of certain criteria that are deemed necessary to declare an experiment as passed.
Tune fault weightage: Set the weight for the fault, which sets the importance of the fault relative to the other faults in the experiments. This is used to calculate the resilience score of the experiment.
c. To add a fault that runs in parallel to another fault, point your mouse below an existing fault, and then select Add.
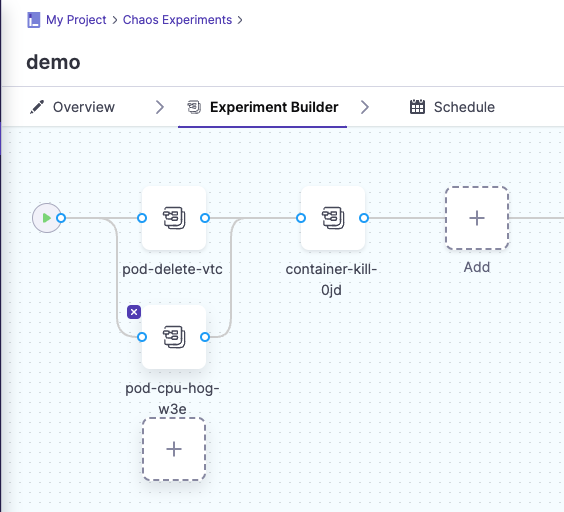
In Experiment Builder, faults that are stacked vertically run in parallel, and faults or groups of parallel faults run in sequence from left to right.
If you select Templates from Chaos Hubs:
a. Select an experiment template from a chaos hub.
Select Experiment Type to see available chaos hubs to select templates from. Select a template to see a preview of the faults included.
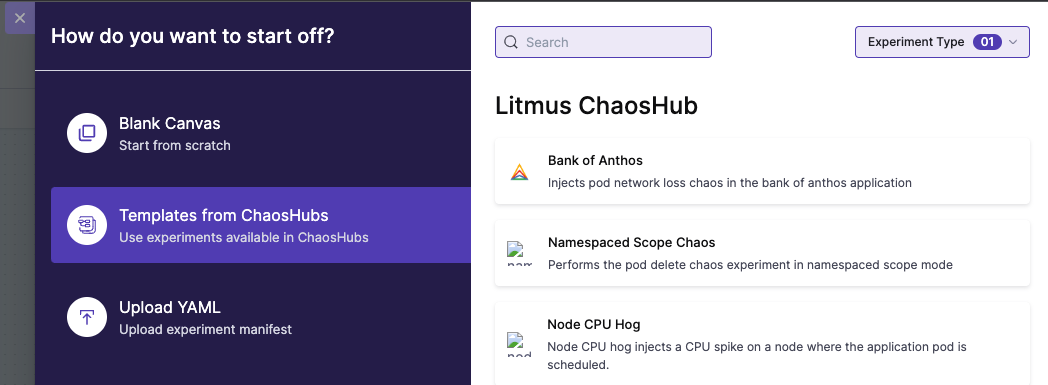
You can edit the template to add more faults or update the existing faults.
If you select Upload YAML:
a. Upload an experiment manifest YAML file to create the experiment.
You can edit the experiment to update the existing faults or add more of them.
4. Save the experiment.

Now, you can choose to either run the experiment right away by selecting the Run button on the top, or create a recurring schedule to run the experiment by selecting the Schedule tab.
Advanced experiment setup options
You can select Advanced Options on the Experiment Builder tab to configure the advanced options (described below) while creating an experiment for a Kubernetes chaos infrastructure:
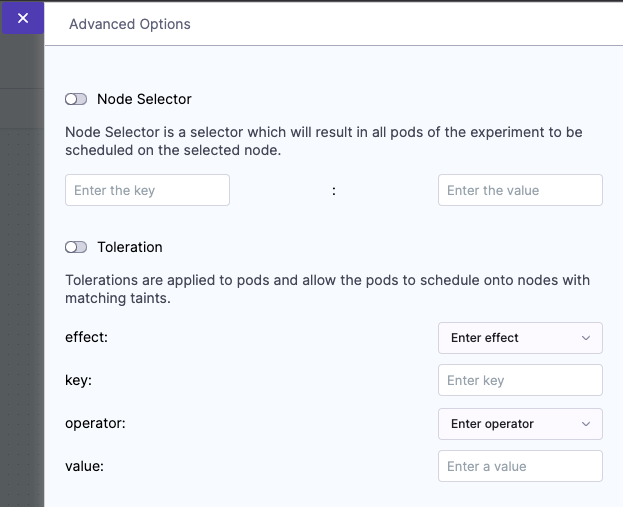
General options
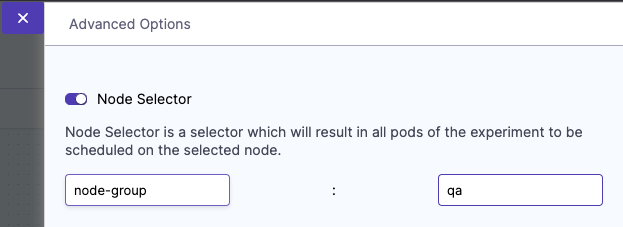
Node Selector
Specifies the node on which the experiment pods will be scheduled. Provide the node label as a key-value pair.
Can be used with node-level faults to avoid the scheduling of the experiment pod on the target node(s).
Can be used to limit the scheduling of the experiment pods on nodes that have an unsupported OS.
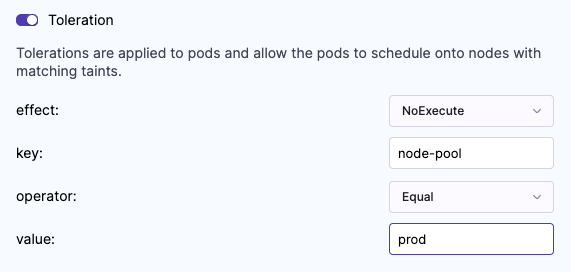
Toleration
Specifies the tolerations that must be satisfied by a tainted node to be able to schedule the experiment pods. For more information on taints and tolerations, go to the Kubernetes documentation.
Can be used with node-level faults to avoid the scheduling of the experiment pod on the target node(s).
Can be used to limit the scheduling of the experiment pods on nodes that have an unsupported OS.